게시판 |
| 상위분류 : 잡필방 | 중위분류 : 서류가방 | 하위분류 : 전산과 컴퓨터 |
| 작성자 : 문시형 | 작성일 : 2016-01-29 | 조회수 : 10,360 |
제 목 : 릴레이션과 관계의 개념
릴레이션(Relation)의 개념
관계형 데이터베이스 관리 시스템(RDBMS: Relational DataBase Management System)에 구현된 테이블의 개념은 수학의 집합이론에서 말하는 릴레이션(Relation)이라는 학술적인 개념과 비록 차이가 있지만, 이러한 테이블을 학술적인 릴레이션 개념에 대응(사상 - 寫像 - mapping)시키면 관계형 데이터베이스 모델을 직관적으로 이해하는데 많은 도움이 될 것이다.
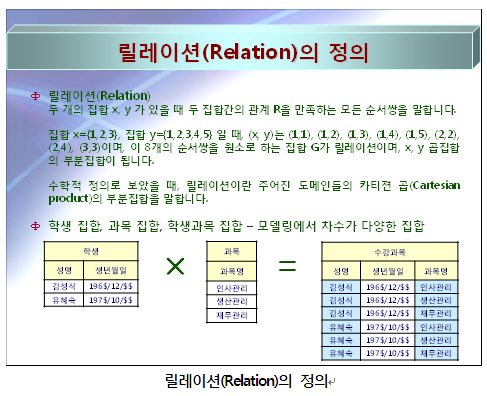
릴레이션(Relation)의 정의에서릴레이션이란 집합 x = {1, 2, 3}과 집합 y = {1, 2, 3, 4, 5} 사이에 관계 R을 만족하는 모든 순서쌍이라고 하였다. 학술적인 릴레이션 개념을 학생이라는 실체유형(테이블)에 대응(Mapping)시켜 보면, 학생이라는 실체유형은 집합 “성명” = {김성식, 유혜숙}과 집합 “생년월일” = {196$/12/$$, 197$/10/$$} 사이에 관계 R을 만족하는 모든 순서쌍의 부분집합이 되는 것이다. “수강과목”이라는 실체유형은 “학생” 집합과, “과목” 집합의 주어진 도메인(속성이 갖는 모든 값의 집합)의 카티젼 곱(다대다곱집합)에 의한 부분집합이 되는 것이다.
이러한 이유로 논리 데이터 모델링에서 다루는 실체유형 및 데이터베이스 설계에서 다루는 테이블이 집합의 성격을 갖게 되는 것이다.
아래 그림 릴레이션(Relation)의 개념에는 평면파일(Flat File)과는 구별되는 관계형 모델의 릴레이션을 간략하게 보여주고 있으며, 예제로 고객 릴레이션을 소개하고 있다. 수학의 집합이론에 근거한 관계형 모델 이론에서는 릴레이션(Relation)이라 하며, 논리 데이터 모델링에서는 실체유형(Entity Type)이라 하고, 관계형 데이터베이스에서는 이것을 테이블(Table)이라 한다. 테이블 이름인 고객이 학술적인 집합 이론에서는 릴레이션의 이름이 되는 것이다. 따라서 고객 테이블은 고객 릴레이션이며 고객이라는 실체유형인 것이다.
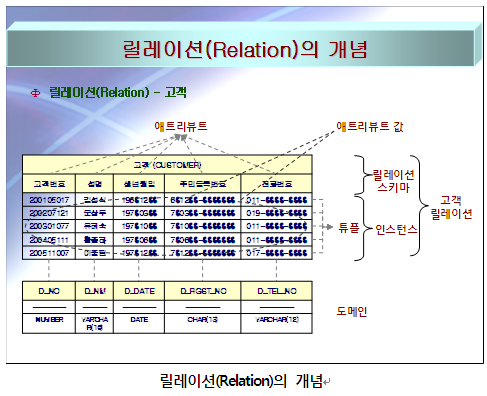
위의 그림 릴레이션(Relation)의 개념에는 릴레이션에 대한 의미를 도식화해서 보여주고 있다. 관계형 모델 이론의 관점에서 이것을 설명해 보고자 한다.
어떤 릴레이션 R이 n개의 도메인(Domain ? 어떤 속성이 취할 수 있는 모든 값의 집합) D1, D2, …, Dn(도메인은 서로 같을 수도 있음) 상에서 정의될 때, 릴레이션(Relation)의 개념에서 볼 수 있는 것과 같이 릴레이션 스키마(Relation Schema - 구조)와 릴레이션 인스턴스(Relation Instance ?릴레이션에 발생된 행들)로 구성된다.
릴레이션 R의 스키마는 릴레이션 이름 R과 일정수의 애트리뷰트 A1, A2, …, An의 집합으로 구성되는데 편의상 R(A1, A2, …, An)으로 표기한다.이러한 릴레이션의 스키마를 관계형 데이터베이스 관점에서 표현하면테이블 “고객”의 구조는 테이블 이름 “고객”과 일정수의 컬럼“고객번호”, “성명”, “생년월일”, …, “전화번호”의 집합으로 구성되는데 편의상 고객(고객번호, 성명, 생년월일, …, 전화번호)로 표기한다.
여기서 각각의 애트리뷰트 Ai(i = 1, 2, …,n)는 도메인 D1, D2, …, Dn의 한 도메인 Di와 정확히 대응된다.이것을 관계형 데이터베이스 관점에서 표현하면,여기서 각각의 컬럼 C(고객번호, 성명, 생년월일…, 전화번호)는 도메인 D(NUMBER, VARCHAR(10), DATE, …, VARCHAR(12))에 정확히 대응된다.
릴레이션 R의 인스턴스는 어느 한 시점에 릴레이션 R에 포함되어 있는 튜플(Tuple = Row)의 집합을 말한다. 하나의 튜플은릴레이션 R의 스키마에 정의된 각 애트리뷰트에 대응하는 값, V(V1, V2, …, Vn)으로 구성된다. 여기서 값 Vi는 애트리뷰트 Ai의 값으로서 Ai가 취할 수 있는 도메인 Di의 하나의 원소 값인 것이다.(도메인은 어떤 애트리뷰트가 취할 수 있는 모든 값을 말하기 때문에, 애트리뷰트의 값 Vi는 도메인 Di의 값 중에 취할 수 있는 하나의 원소 값이다.)이것을 관계형 데이터베이스 관점에서 표현하면,테이블 “고객”의 인스턴스는 어느 한 시점에 테이블 “고객”에 포함되어 있는 로우(Row: 행)의 집합을 말한다. 하나의 로우는 테이블 “고객”의 스키마에 정의된 각 컬럼(Column)에 대응하는 값, (200105017, 김성식, 196$/12/$$, 6$12$$-$$$$$$, 011-$$$$-$$$$, - - -)으로 구성된다. 여기서 값 200105017은 컬럼“고객번호”의 값으로서 “고객번호”가 취할 수 있는 도메인 “NUMBER”의 값 중에 하나의 원소 값인 것이다.
릴레이션 R의 정의에서 애트리뷰트의 개수, 즉 n을 릴레이션 R의 차수(Degree)라고 한다. 차수 1인 릴레이션을 1차 릴레이션, 차수가 2인 즉, 애트리뷰트(속성)의 개수가 2인 릴레이션을 2차 릴레이션, 차수가 n 즉, 애트리뷰트(속성)의 개수가 n인 릴레이션을 n차 릴레이션이라고 하며, 릴레이션 R이 가지는 튜플(Row = Record)의 수를 릴레이션 R의 기수성(Cardinality)라고 한다. 이 기수성의 개념은 관계(Relationship)가 갖는 기수성의 개념과는 다소 차이가 있다. 위의 그림 릴레이션(Relation)의 개념에 있는 “고객”릴레이션의 차수는 5이고, 기수성도 5인 릴레이션인 것이다.
릴레이션 스키마와 릴레이션 인스턴스는 현실 세계의 실체유형(Entity Type ? 테이블)과 실체집합(Entity Set ? 테이블의 행 전체)에 비유하여 이해할 수 있다. 즉, 릴레이션 스키마는 릴레이션의 논리적 구조를 정의한 것이고, 실체유형(테이블)의 스키마는 실체유형(테이블)의 논리적 구조를 정의한 것이다. 또 릴레이션 인스턴스는 어느 한 시점의 릴레이션의 내용, 즉 튜플 전체를 말하고, 실체유형(테이블)의 인스턴스는 어느 한 시점의 실체유형(테이블)의 내용, 즉 저장된 실체집합(테이블의 행 전체)을 의미하는 것이다. 이러한 실체집합(Entity Set)을 실체의 복수형 Entities로 표현하는 서적도 많이 있다.
릴레이션 인스턴스나 실체유형(테이블)의 인스턴스(실체집합 - 테이블의 행 전체)는 시간이 지남에 따라 그 내용이 생성, 소멸 되는 동적인 성질을 가지고 있는 반면에 릴레이션스키마나 실체유형(테이블) 스키마는 쉽게 변하는 것이 아니므로 시간에 따라 잘 변하지 않는 정적인 성질을 가지고 있다.
관계(Relationship)
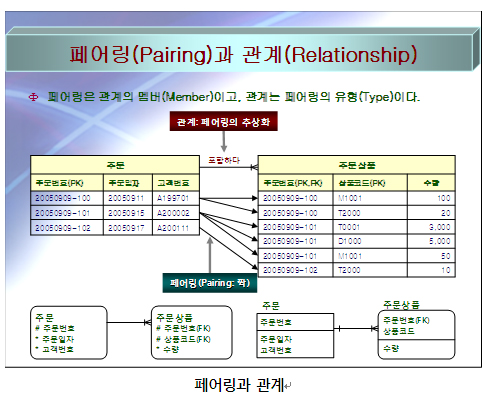
관계(Relationship, 關係): 관계란 하나 또는 두 개의 실체유형(Entity Type)으로부터 실체(Entity)를 연결시키는 업무적인 이유를 말한다. 실체유형이 실체의 집합체인 것과 마찬가지로 관계(유형) 또한 하나 또는 두 개의 실체유형으로부터 업무적인 이유에 의해서 실체가 연결되어 있는 페어링(멤버)의 집합체(Set)이다.
페어링(Pairing, 짝): 페어링이란 우리말로 번역하면 짝이라고 할 수 있는데, 통상적으로 페어링이라는 발음 그대로 사용하고 있다. 어떤 실체유형(Entity Type)의 실체(Entity)가 자기 자신 또는 다른 실체유형(Entity Type)의 실체(Entity)와 업무적인 이유에 의해서 연결되어 있는 것을 페어링이라고 한다.
아래 그림 페어링과 관계를 보면 실체유형 “주문”의 실체인 “주문번호”가 ‘20050909-100’인 주문은 실체유형 “주문상품”의 실체인 “상품코드”가 ‘M1001’, ‘T2000’과 연결되어 페어링(짝)을 이루고 있고, 실체유형 “주문”의 실체인 “주문번호”가 ‘20050909-101’인 주문은 실체유형 “주문상품”의 실체인 “상품코드”가 “T0001”, “D1000”, “M1001”과 연결되어 페어링(짝)을 이루고 있다. 이러한 페어링(멤버)을 추상화(Abstraction)하면, 페어링(멤버)의 유형인 관계(유형)를 생성할 수 있는 것이다. 즉, 페어링은 관계의 멤버이고, 관계는 페어링을 추상화한 유형(Type)인 것이다. 이를 달리 표현하면 관계는 페어링의 집합체(Set)라고 할 수 있다.
업무에서 필요로 하는 실체유형을 인식하여 논리 데이터 모델에 표현하는 것이 어렵듯이, 모델링을 진행하면서 관계를 정의하다보면 관계의 도출이 그렇게 쉽지만은 않다는 것을 알게 될 것이다. 우리는 현업과의 모델링 과정중 관계를 인식하기 위하여 현업이 사용하는 용어에서 일반적으로 동사적인 표현에 유의할 필요가 있다. 예를 들어 “고객은 상품을 주문한다.”“사원은 부서에 소속되어 있다.” 에서 “주문한다”, “소속되어 있다”와 같은 표현이 대부분 관계를 나타낸다고 하겠다.
관계를 도출함에 있어서 아래 그림 관계 유형 분류에서 보는 바와 같이 세 가지 유형의 관계를 고려하면 상당히 도움이 될 것이다. 이러한 관계 유형 분류는 그저 관계를 도출함에 있어서 도움을 주고자 하는 것이니 관계 유형을 반드시 기록할 필요는 없다.

관계는 논리 데이터 모델링의 대상인 실체유형이나 속성과는 달리 업무 규칙을 표현하는 몇 가지 중요한 특성을 가지고 있다.
관계의 식별성(Identification), 선택성(Optionality), 기수성(Cardinality, Degree), 페어링의 비전이성(Non-transferability)이 관계에서 살펴봐야 할 중요한 특성인데, 식별성, 선택성, 기수성은 논리 데이터 모델링을 지원하는 케이스 툴에서 표기법을 지원하지만, 페어링의 비전이성에 대한 표기법은 서양의 몇몇 서적에서만 이론을 얘기할 뿐, 현재 우리가 가장 많이 사용하는 케이스 툴에서는 지원이 안되고 있다. 자세한 관계에 대한 특성은 다음에!
| | 목록으로