게시판 |
| 상위분류 : 잡필방 | 중위분류 : 서류가방 | 하위분류 : 전산과 컴퓨터 |
| 작성자 : 문시형 | 작성일 : 2016-01-26 | 조회수 : 6,402 |
제 목 : 정규화(Normalization) 정의
정규화(Normalization) 정의
정규화는 이미 여러분들이 잘 알고 있는 바와 같이 관계형 데이터 모델 이론에서 중복 정보 정의를 최소화하여 논리 데이터 모델링의 목적인 정확성, 일관성, 단순성, 비 중복성, 안정성을 만족시키는 최적의(Optimal) 개념적 데이터를 일컫는다.
앞선 기고 논리 데이터 모델링 사례 - 구매주문에서 사례를 설명하면서 1, 2, 3차 정규화 사례 및 정규화를 해야만 하는 이유를 설명하였다.
다시 한번 정규화를 해야 하는 이유를 설명한다면, 정규화는 플랫(Flat) 파일에서 발행하는 데이터의 입력이상, 수정이상, 삭제이상이라는 데이터 이상 현상을 제거하여 데이터의 정확성과 일관성을 확보하고자 하는 것이다.
여 기서는 각각의 이론에서 살펴보는 정규화에 대해서 관계형 모델 이론에서 하는 얘기와 두명의 학자, 그리고 논리 데이터 모델링에서 말하는 정규화에 대해서 좀 더 알아보고, 정규화를 해서는 안되는 경우의 사례를 얘기해 보도록 하겠다. 정규화에 대한 기본적인 내용을 알고 싶다면 이전의 글을 다시 한번 읽어 보기를 바란다.

정규화(Normalization)
1차 정규형

1차 정규형
관계형 모델 이론에서는 모든 속성이 하나의 원자적 값을 취하는 릴레이션일 때 이를 1차 정규형이라고 한다라고 하였고, C.J. Date도 이러한 이론에 충실하여 위와 같이 정의를 내렸다. 그런데 여기에서 설명하기 어려운 약간의 문제가 발생하였다. 앞서 기고한 구매 주문 모델에서의 1차 정규화를 설명할 때의 사례는 반복 그룹의 속성을 제거하는 것이 1차 정규화라고 설명하였을 것이다. 이러한 반복 그룹을 제거하여 다른 실체 유형으로 옮기라고 한 사람은 Finkelstein이였는데, 그래서 어떤 책에서는 속성이 단 하나의 원자적 값을 갔는 것을 1차 정규화라고 설명하고 있고, 어떤 책에서는 반복 속성 그룹을 제거하라고 설명이 되어 있는데 이 두 가지 얘기가 모두 1차 정규화를 설명하고 있는 것이다.
2차 정규형
2차 정규형이란 1차 정규화를 실시하여 1차 정규형을 만들고, 2차 정규화를 실시하여 1차 정규형을 만족하면서 2차 정규화를 실시한 릴레이션을 말한다.
아 래 2차 정규형 그림 관계형 모델 이론을 보면, 1차 정규형에 속하고, 키가 아닌 모든 일반 속성들이 후보 키(Candidate Key)에 함수 종속되어야 한다고 하고 있다. 이러한 관계형 모델 이론에 대해서 Finkelstein은 Candidate Key에 함수 종속이라는 용어를 사용 안하고, Primary Key에 부분 종속되는 속성을 식별하여 다른 실체로 옮긴다라고 하고 있다. 하지만 여러분들이 현장에서 논리 데이터 모델링을 진행할 때 반드시 기억해야 하는 내용은 맨 아래에 있는 모든 속성은 반드시 UID(Unique Identifiel, 물리에서는 Primary Key) 전부에 종속되도록 하여야 한다는 것이다.

2차 정규형
3차 정규형
3차 정규형이란 1, 2차 정규화를 실시하여 2차 정규형을 만들고, 3차 정규화를 실시하여 1, 2차 정규형을 만족하면서 3차 정규화를 실시한 릴레이션을 말한다

3차 정규형
여기서도 관계형 모델 이론 에서는 제 2 정규형에 속하고, Non-key 속성들 사이에는 함수 종속 관계가 없어야 한다고 하고 있다. 이러한 용어들은 대학교에서 수업을 받고 수학적으로 이를 증명하는데는 필요하지만 업무 현장에서는 이러한 이론적인 논리보다는 실용적으로 현장에서 사용할 수 있는 UID(Unique Identifiel, 물리에서는 Primary Key)가 아닌 속성간에는 서로 종속될 수 없다는 말이 훨씬 더 유용할 것이다.
정규화 위배
아래 그림 정규화 위배를 보면 고객번호 속성과 고객명 속성이 보인다. 고객명은 고객 실체유형에 성명이라는 속성으로 알 수 있는데, 이는 UID(Unique Identifiel, 물리에서는 Primary Key)가 아닌 속성간에는 서로 종속될 수 없다는 3차 정규화에 위배 된다고 할 수 있다.
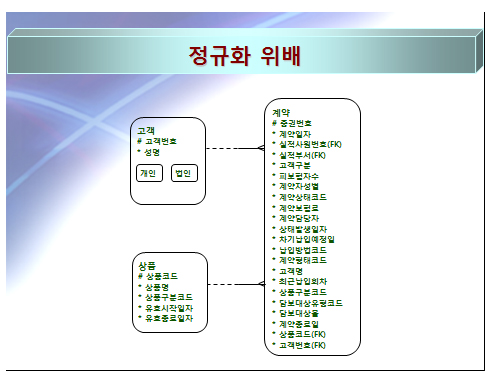
정규화 위배
가 장 쉽다고 보이는 고객명을 살펴 보았고, 이제 좀 더 내용을 살펴 보겠다. 계약 이후 보험료 납입은 납입주기에 따라서 여러 번 발생할 것이다. 하나의 속성은 원자 값을 갖어야 하는데 위의 모델로는 여러 번 납입하는 것을 표현할 수 없다. 이를 위해서는 1차 정규화가 필요한 것이다. 또한 담보 대상물은 계약의 목적에 따라 하나의 계약에 여러 개가 있을 수 있다. 그래서 이 또한 1차 정규화를 해야 하는 속성이다. 필자가 이렇게 모델을 보고서 얘기할 수 있는 것은 이러한 업무에 대한 경험이 있기 때문이다. 즉, 수 많은 속성을 보면서 정규화를 실시 할 때도 업무를 잘 알고 있으면 정규화를 하기가 좀 더 수월 하지만 업무를 잘 모른다면 정규화 또한 어려워 지는 것이다. 이러한 아래 그림은 1, 2, 3차 정규화를 실시한 3차 정규형 모델이다.
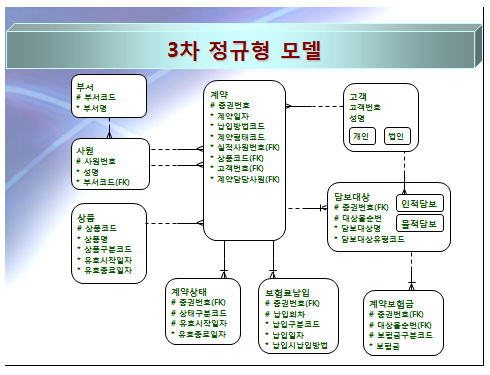
3차 정규형 모델
정규화를 실시하지 않아도 되는 첫째 사례
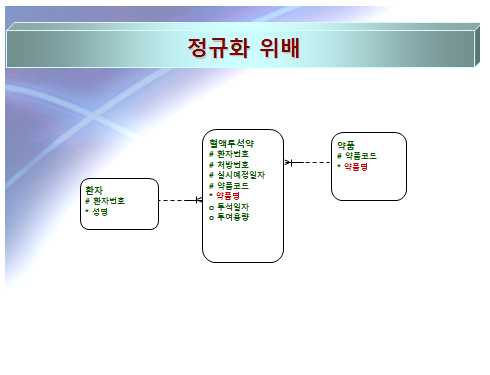
위 그림 정규화 위배는 병원 업무에서 발생하는 모델이다. 혈액약투석 실체유형을 보면 약품코드 밑에 약품명이 보일 것이다. 이는 분명히 3차 정규화 위배이다. 그런데 여기서 업무를 살펴 보면 이 속성의 값이 약품 실체유형에 있는 약품명이 아닐 때가 있다. 어떤 경우냐 하면 투석을 해야 할 약을 환자 들이 직접 가지고 와서 맞는 경우가 있다. 이 때 이 약품 코드는 약품 테이블에 ‘자가약’으로 등록되어 있고, 약품명은 환자 측에서 가지고 온 약품의 명칭을 기록하는 것이다. 물론 이 약품이 그 병원에 등록되어 있을 수도 있고, 등록이 안 되어 있는 경우 등록하고 사용할 수도 있겠지만 병원에서 받아야 할 약품 값을 계산할 때 빠져야 하므로 다양한 이후의 업무적인 이유 때문에 약품 코드에 등록을 안하고 자가약으로 정의하고 약품명을 여기에 입력하는 것이다. 이렇듯 정규화가 데이터의 이상 현상을 제거하는 하는 가장 큰 목적이 있더라도 모델링 이론 보다는 업무가 우선시 되는 것이 중요하다는 것을 인식하기 바란다.
정규화를 실시하지 않아도 되는 둘째 사례
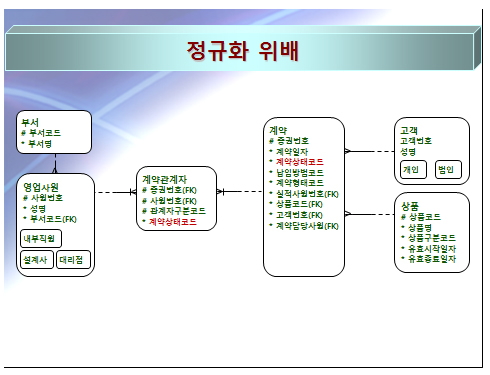
위 그림 정규화 위배는 손해보험 업무에서 발생하는 모델이다. 계약관계자 실체유형을 보면 계약상태코드 속성이 보일 것이다. 이 속성은 계약 실체유형의 속성으로 계약의 상태가 정상, 취소, 실효 등을 나타내는 속성이다.
손해 보험 회사의 업무를 보면 많은 사람들이 보험에 가입하는데, 보험 가입 이후에 취소를 한다거나, 3개월 동안 보험료를 납입 못하면 보험 계약이 실효가 됐다가 보험료를 납입하면 다시 부활이 되고 하는 일들이 비일비재하다.
또한 장기 보험은 보험 기간이 오랜 기간이지만 일반 보험이나 자동차 보험은 1년 단위의 계약이며 보험 계약기간이 끝난 건도 매우 많을 것이다.
영업 사원은 아침에 출근하면 가장 궁금한 사항이 현재 정상으로 유지되고 있는 보험계약 건에 관심이 제일 많다. 왜냐하면 정상으로 유지되고 있는 계약 건이 많을수록 설계사나 대림점의 수당, 수수료가 많을 테니까 수당, 수수료는 봉급 생활자의 급여와 같은 것이기 때문이다.
예를 들어 어떤 설계사가 수만 건의 계약을 여태까지 진행하였는데 현재 정상으로 유지되고 있는 건이 100건 정도라고 해보자. 설계사는 아침에 출근하면 정상으로 유지되고 있는 계약건을 수시로 조회한다. 그래서 본인의 사원번호를 치고 조회를 하는데 계약관계자 실체유형에 계약상태코드가 없다면 수만 건의 데이터를 읽어서 계약과 조인을 한다음 계약상태코드가 정상인 건을 가지고 올 것이다. 즉, 정상적인 계약건을 찾는데 수만건의 데이터를 읽고 이를 계약건과 조인한 다음 필터링을 통해서 데이터를 가져 오는 것이다. 즉, 쓸데없이 한번 조회를 할 때 마다 수만 건의 데이터를 읽는 것이다. 그래서 아침만 되면 전국 각지의 사무실에서 너무 많을 데이터를 읽고 필터링을 통해서 데이터를 가져오기 때문에 도저히 속도가 나지 않으므로 시스템에 문제가 많게 된다.
이를 해결하려면 반 정규화를 수행하는 것이다. 그래서 계약 실체유형의 계약상태코드를 계약관계자 실체유형에 가져가면 수 많은 데이터 중에 정상인 건만 바로 읽어서 계약과의 조인에서도 필터링을 안하고 바로 원하는 데이터만 가져올 수 있어 수행 속도가 원할해질 것이다. 즉, 수행 속도를 위해서 반 정규화를 수행하는 것이다.
기억해야 할 것은 수행 속도를 위해서 반 정규화를 수행하는 경우에는 반드시 데이터 값의 정합성이 깨지지 않도록 반드시 프로그램 적으로 해결해야 한다는 것이다.
| | 목록으로